
INF 1771 – Inteligência Artificial
Aula 15 – Support Vector Machines (SVM)
Edirlei Soares de Lima
<elima@inf.puc-rio.br>

Formas de Aprendizado
•
Aprendizado Supervisionado
–
–
–
–
Árvores de Decisão.
K-Nearest Neighbor (KNN).
Support Vector Machines (SVM).
Redes Neurais.
•
•
Aprendizado Não Supervisionado
Aprendizado Por Reforço

Aprendizado Supervisionado
•
Observa-se alguns pares de exemplos de entrada e
saída, de forma a aprender uma função que mapeia
a entrada para a saída.
•
•
Damos ao sistema a resposta correta durante o
processo de treinamento.
É eficiente pois o sistema pode trabalhar
diretamente com informações corretas.

Support Vector Machine
•
•
Proposto em 1995 pelo russo Vladimir Vapnik.
Consiste em um método de aprendizado que tenta encontrar
a maior margem para separar diferentes classes de dados.
•
•
Pertence à classe de algoritmos de aprendizado
supervisionado.
A essência do SVM é a construção de um hiperplano ótimo,
de modo que ele possa separar diferentes classes de dados
com a maior margem possível.
Support Vector Machine
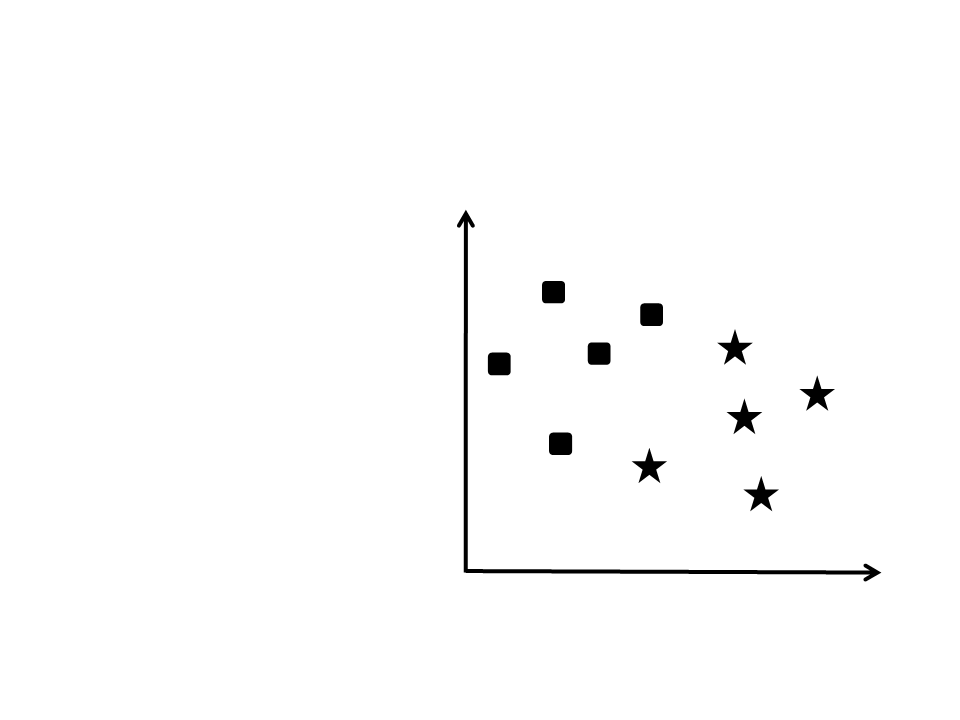
•
Como separar essas duas
classes?
Support Vector Machine
•
•
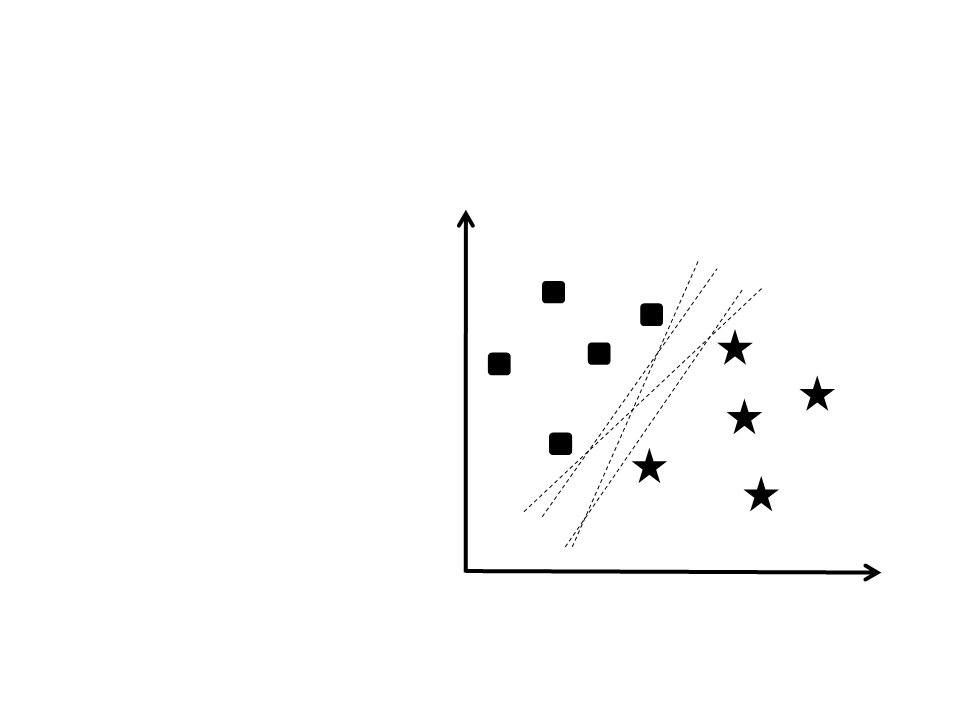
Como separar essas duas
classes?
–
Existem diversas retas que
podem ser traçadas para
separar os dados.
Qual delas é a melhor
opção?
Support Vector Machine
•
•
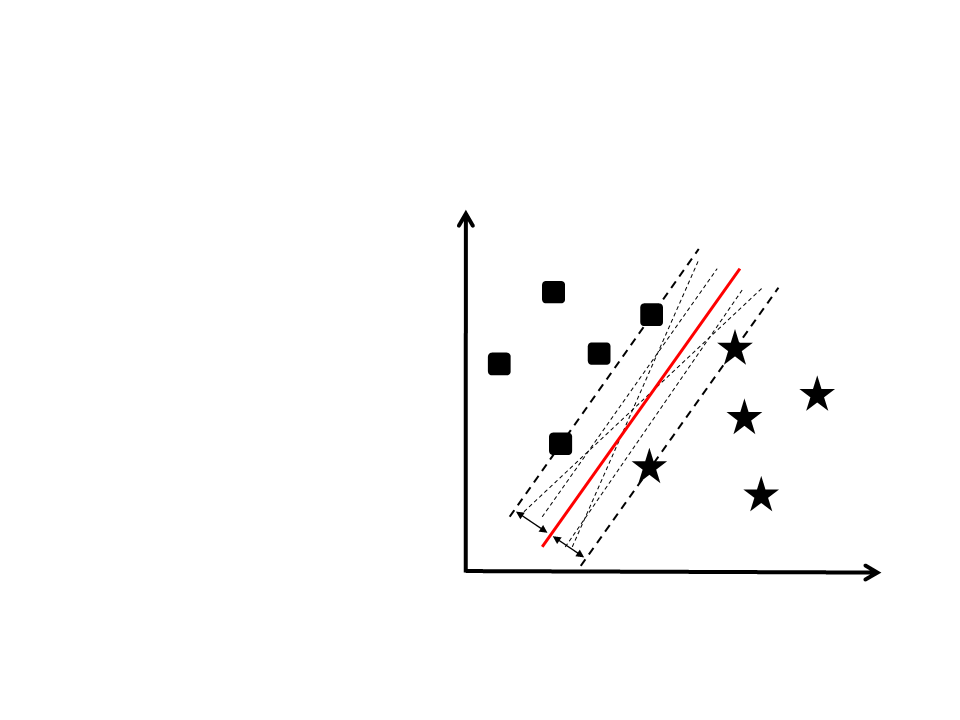
Como separar essas duas
classes?
–
Existem diversas retas que
podem ser traçadas para
separar os dados.
Qual delas é a melhor
opção?
–
Hiperplano ótimo!
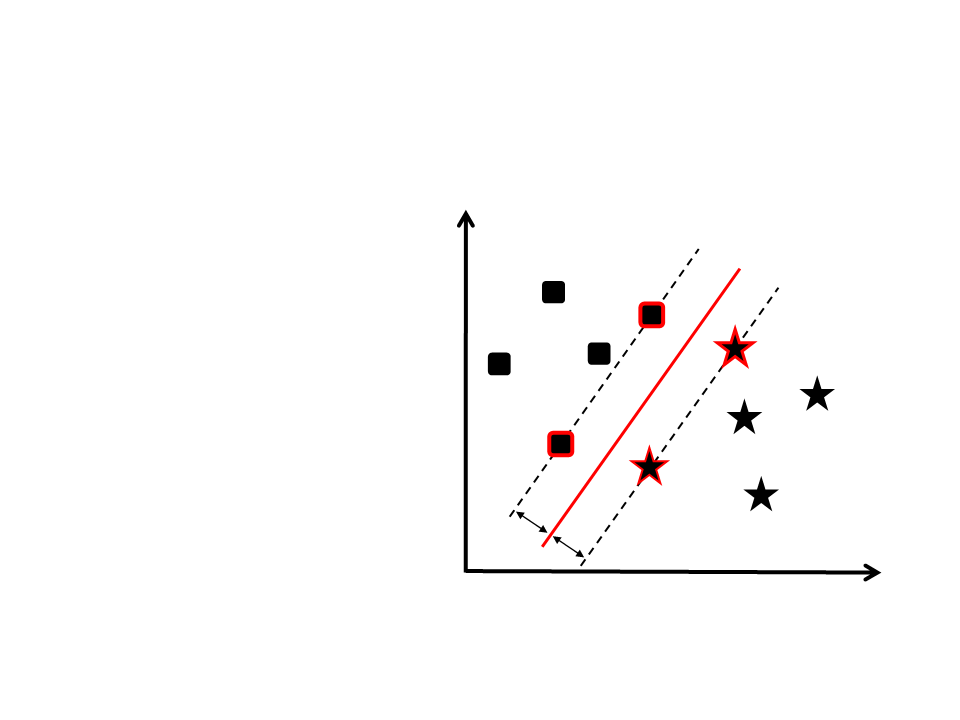
Vetores de Suporte
•
•
•
Servem para definir qual será o
hiperplano.
São encontrados durante a fase
de treinamento.
Os vetores de suporte são os
exemplos de treinamento
realmente importantes. Os
outros exemplos podem ser
ignorados.
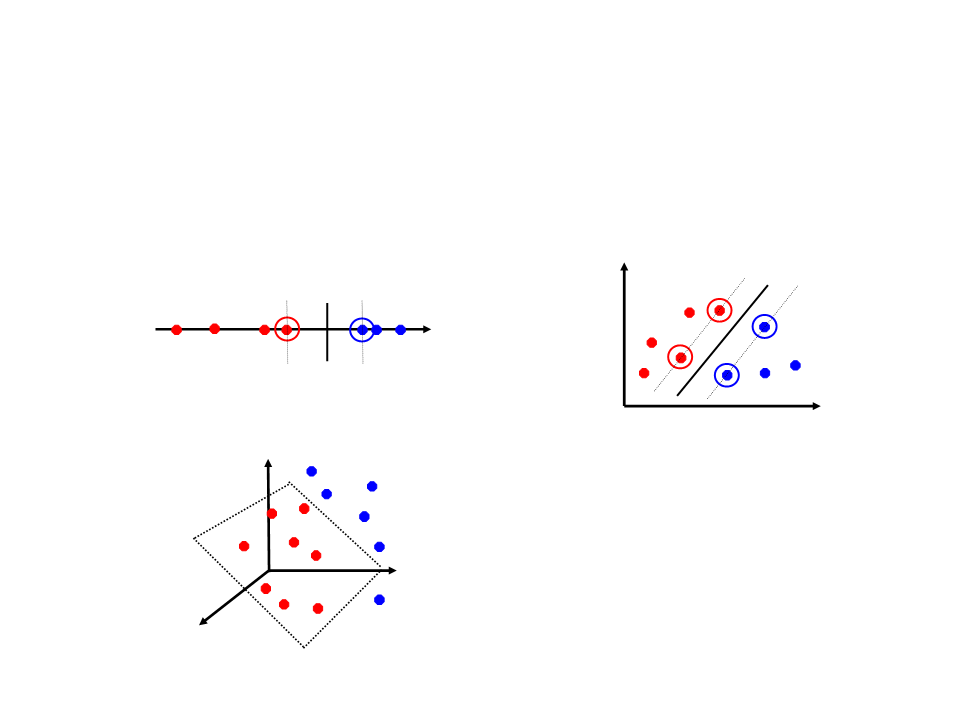
Support Vector Machine
•
Hiperplano:
–
Espaço 1D = Ponto
Espaço 2D = Reta
–
Espaço 3D = Plano

Support Vector Machine
•
•
A aplicação de um método puramente linear para classificar
um conjunto de dados pode sofrer com dois problemas
bastante comuns:
–
–
Outliers
Exemplos rotulados erroneamente
Mesmo assim o SVM ainda assim pode ser aplicado através do
uso do parâmetro C (soft margin - variáveis de folga)
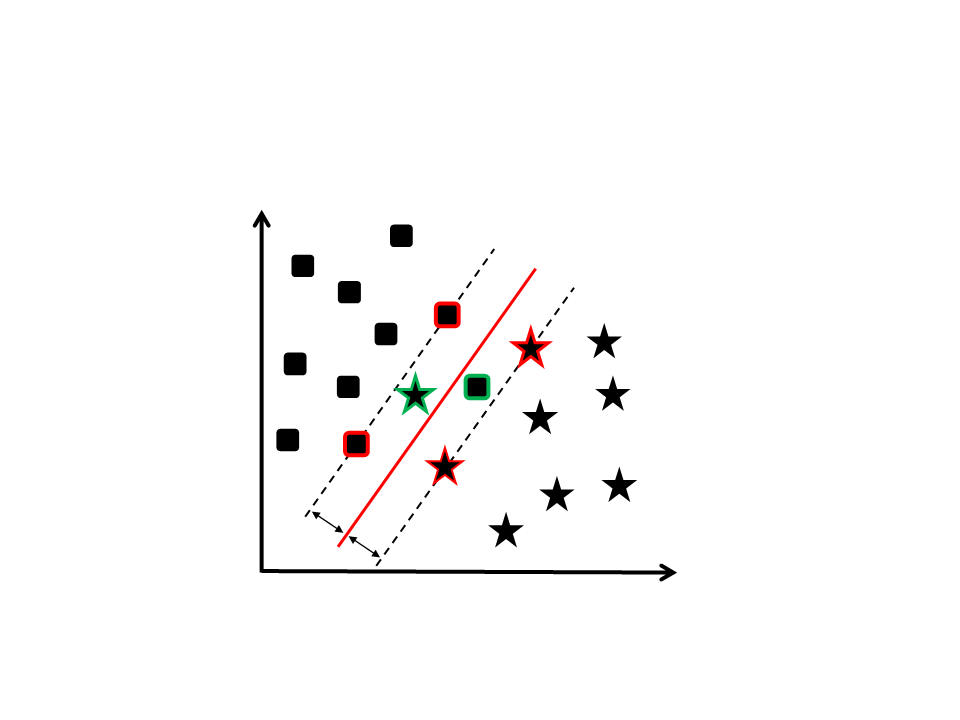
Soft Margin

Support Vector Machine
•
Em alguns problemas não é possível separar as
classes linearmente mesmo utilizando a margem de
folga.
•
•
Na realidade, a grande maioria dos problemas reais
não são separáveis linearmente.
O que fazer?
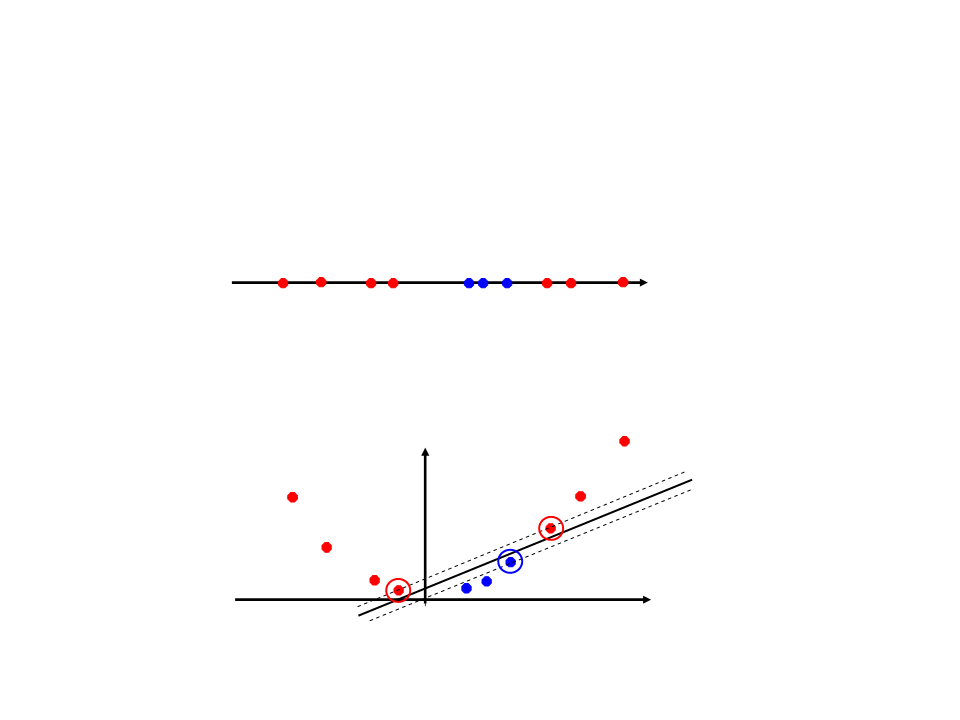
SVM Não-Linear
•
•
O que fazer quando os dados não são linearmente separáveis?
x
A abordagem utilizada pelo SVM para resolver esse tipo de
problema consistem em mapear os dados para um espaço de
dimensão maior:
x2
x
SVM Não-Linear
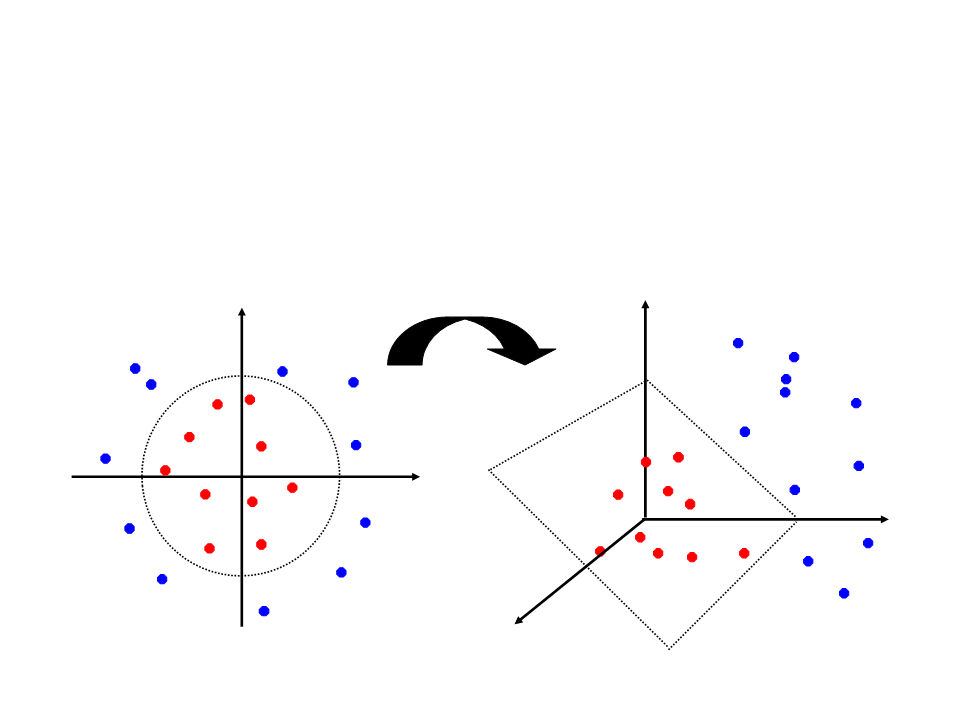
•
O espaço de atributos original pode ser mapeado em um
espaço de atributos de dimensão maior onde o conjunto de
treinamento é linearmente separável:
Φ: x → φ(x)
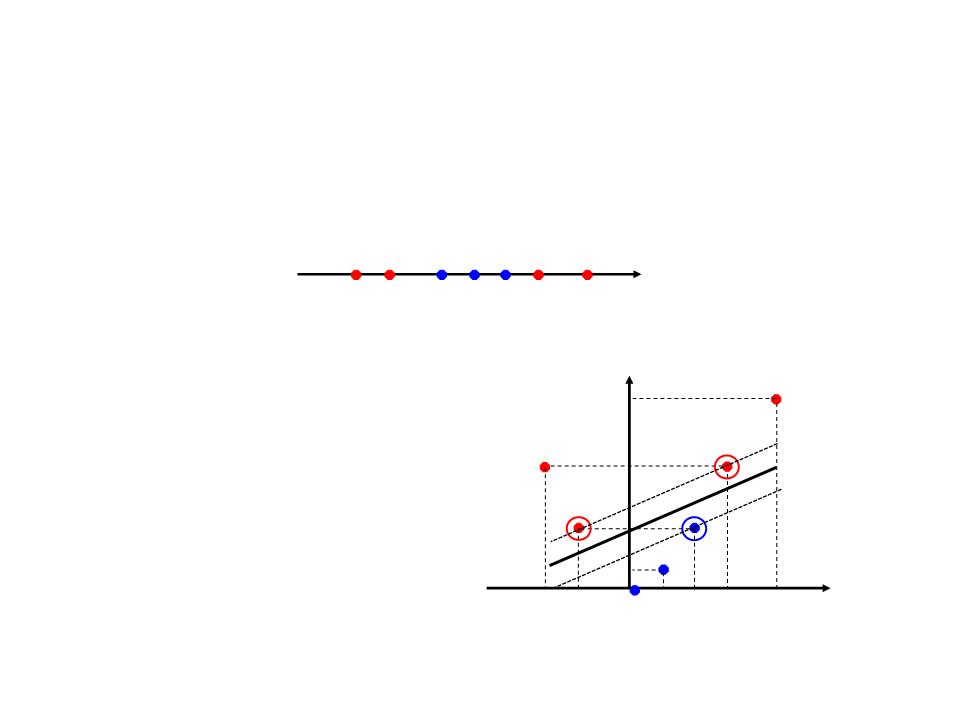
SVM Não-Linear Exemplo
•
•
Considerando o seguinte conjunto de exemplos de treinamento que não
são linearmente separáveis:
X
-3
-2
0
1
2
3
5
Elevando para uma dimensão linearmente separável (R1 → R2):
25
9
Kernel: φ(x) = (x, x2)
4
1
•
X
-3
-2
0
1
2
3
5
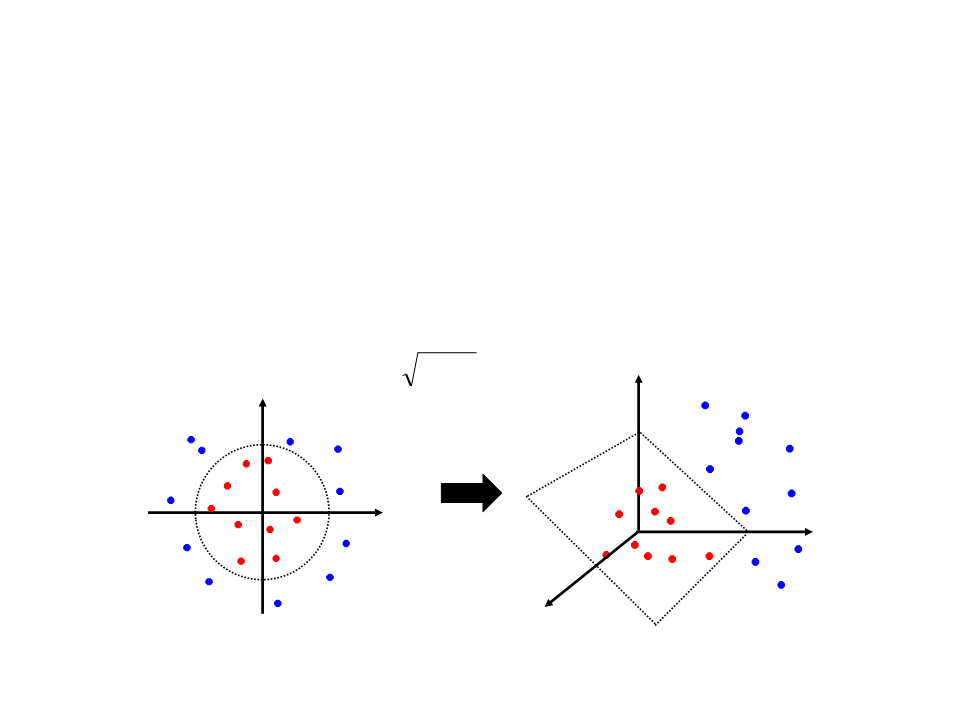
SVM Não-Linear Exemplo
•
•
A mesma metodologia pode ser aplicada em um espaço 2D de características
(
2 3
R → R ).
A única diferença é a necessidade de uma nova função de kernel. Um exemplo
de função de kernel aplicável nesse caso seria:
2 2
(x1, x2) →(z1, z2, z3) =(x1 , 2x1x2 , x2)
z2
z1
z3
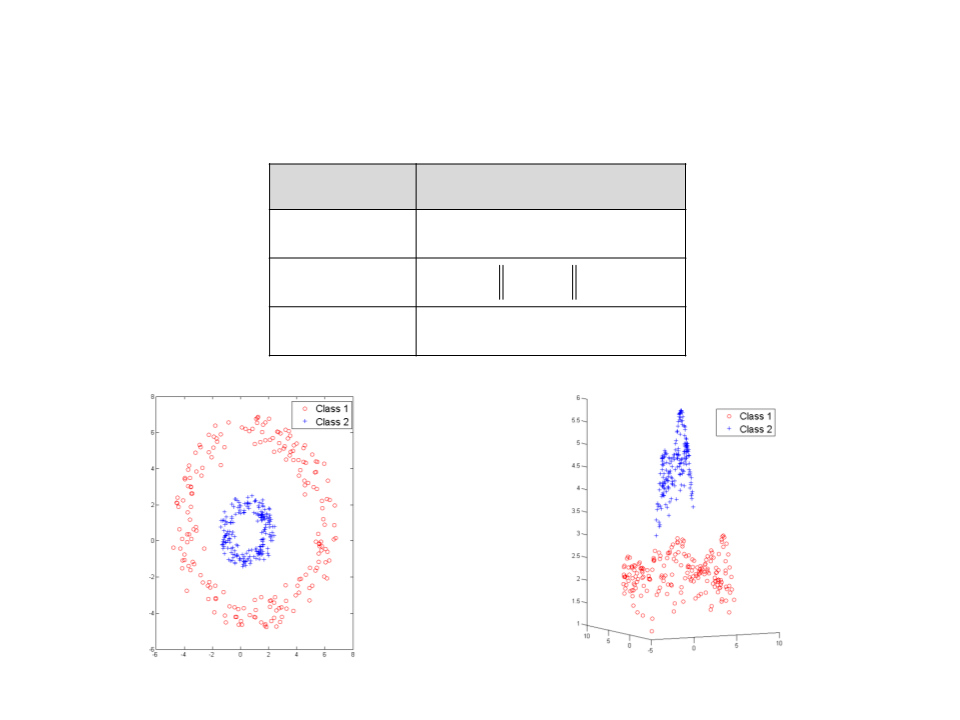
Funções de Kernel
Kernel
Função (xi ,xj )
d
Polinomial
Gaussiano
Sigmoidal
((xi xj ) + k)
2
exp(− xi − xj )
tanh((xi xj ) + k)

Polynomial Kernel

Support Vector Machine
•
•
•
O SVM foi originalmente concebido para lidar com
classificações binárias.
Entretanto, a maior parte dos problemas reais requerem
múltiplas classes.
Para se utilizar uma SVM para classificar múltiplas classes é
necessário transformar o problema multi-classe em vários
problemas da classes binárias
–
–
Um contra o resto.
Pairwise.

Aplicação
•
•
Antes de aplicar uma SVM para classificar um
conjunto de dados é necessário responder algumas
questões:
–
–
Quais funções de kernel utilizar?
Qual o valor do parâmetro C (Soft Margin)?
Validações cruzadas (cross‐validations).

Vantagens e Desvantagens
•
•
Vantagens:
–
–
–
Consegue lidar bem com grandes conjuntos de exemplos.
Trata bem dados de alta dimensão.
O processo de classificação é rápido.
Desvantagens:
–
É necessário definir um bom Kernel.
–
O tempo de treinamento pode ser bem longo dependendo
do número de exemplos e dimensionalidade dos dados.

LIBSVM
•
http://www.csie.ntu.edu.tw/~cjlin/libsvm/
–
–
http://www.python.org/download/
http://www.gnuplot.info/download.html
•
•
Bases de Exemplos:

Leitura Complementar
•
•
•
Mitchell, T. Machine Learning, McGraw–Hill
Science/Engineering/Math, 1997.
Duda, R., Hart, P., Stork, D., Pattern Classification,
John Wiley & Sons, 2000
Cristianini, N., Shawe-Taylor, J., An Introduction
to Support Vector Machines and Other Kernel-
based Learning Methods, Cambridge University
Press, 2000.